About me |
|
I am Computer Vision Researcher at the Computer Vision Department at Mohamed Bin Zayed University of Artificial Intelligence advised by Prof. Fahad Khan, where I work on designing accurate, fast, and memory-efficient computer vision architectures for edge devices. I have a PhD in Computer Vision from MBZUAI, and I also have mixed experience between conducting pure academic research and contributing to international products in the industry. I worked as a Machine Learning Engineer at Valeo Egypt and Teaching/Lecturer Assistant at the Faculty of Computer and Information Sciences, Ain Shams University. During my PhD, I strive to build state-of-the-art methods that are efficient, fast, robust, and reliable, that can be used for mobile vision applications. Email / Resume / Google Scholar / Github |

|
Selected Publications |
|
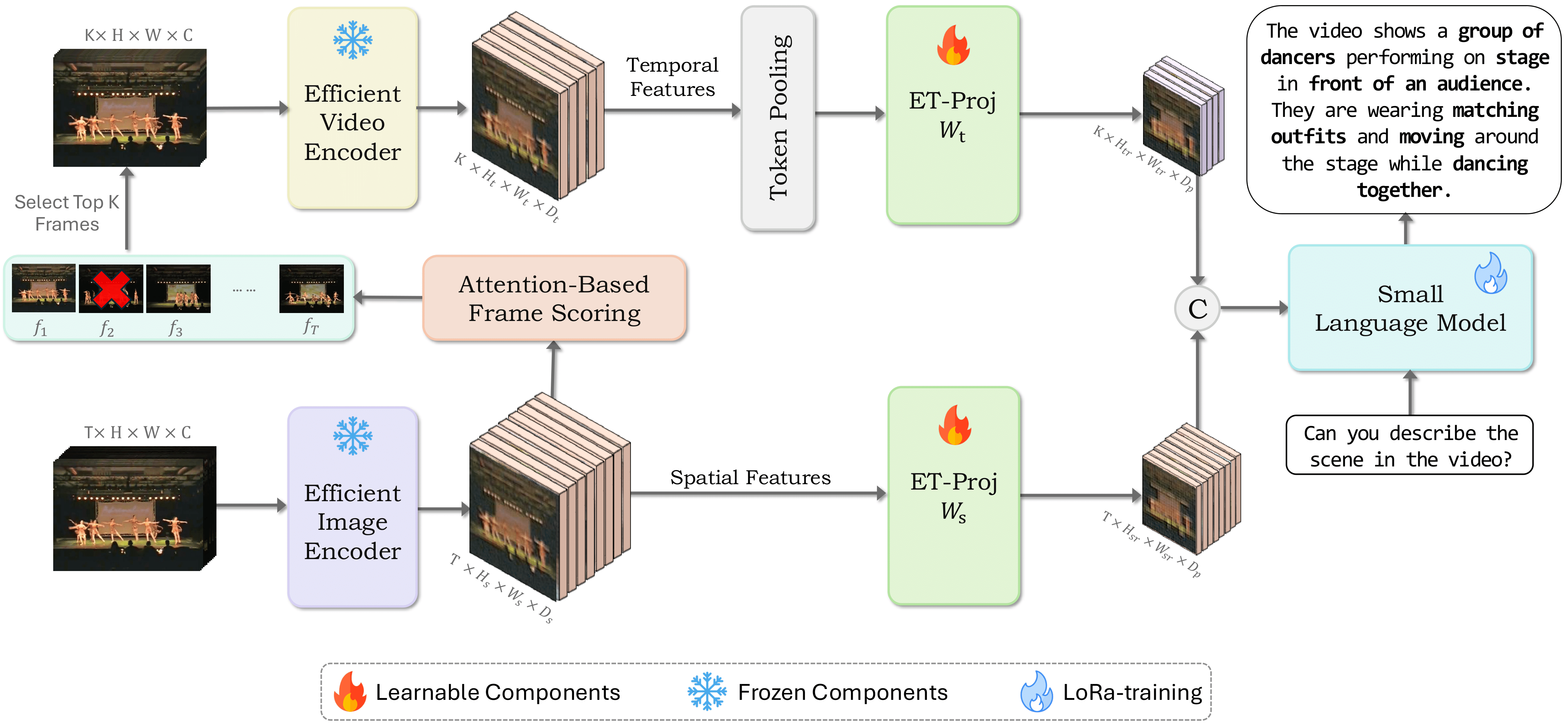
Mobile-VideoGPT: Fast and Accurate Video Understanding Language Model
Abdelrahman Shaker, Muhammad Maaz, Chenhui Gou, Hamid Rezatofighi, Salman Khan, Fahad Khan Paper / YouTube / Models / Project Website Mobile-VideoGPT is an efficient multimodal framework designed to operate with fewer than a billion parameters. Unlike traditional video large multimodal models, it integrates lightweight dual visual encoders, efficient projectors, and a small language model (SLM), enabling real-time inference on resource-constrained platforms. It further introduces an Attention-Based Frame Scoring mechanism for key-frame selection and an efficient token projector that prunes redundant visual tokens while preserving essential contextual cues. Evaluations across six video understanding benchmarks (e.g., MVBench, EgoSchema, NextQA, PerceptionTest) show that Mobile-VideoGPT-0.5B can generate up to 46 tokens per second while outperforming existing 0.5B-parameter competitors. |
|
VideoMathQA: Benchmarking Mathematical Reasoning via Multimodal Understanding in Videos
Hanoona Rasheed, Abdelrahman Shaker, Anqi Tang, Muhammad Maaz, Ming-Hsuan Yang, Salman Khan, Fahad Khan Paper / Project Website / Dataset VideoMathQA is a benchmark designed to evaluate mathematical reasoning in real-world educational videos. It requires models to interpret and integrate information from three modalities — visuals, audio, and text — across time. The benchmark tackles the needle-in-a-multimodal-haystack problem, where key information is sparse and distributed across different modalities and moments in the video. |
|
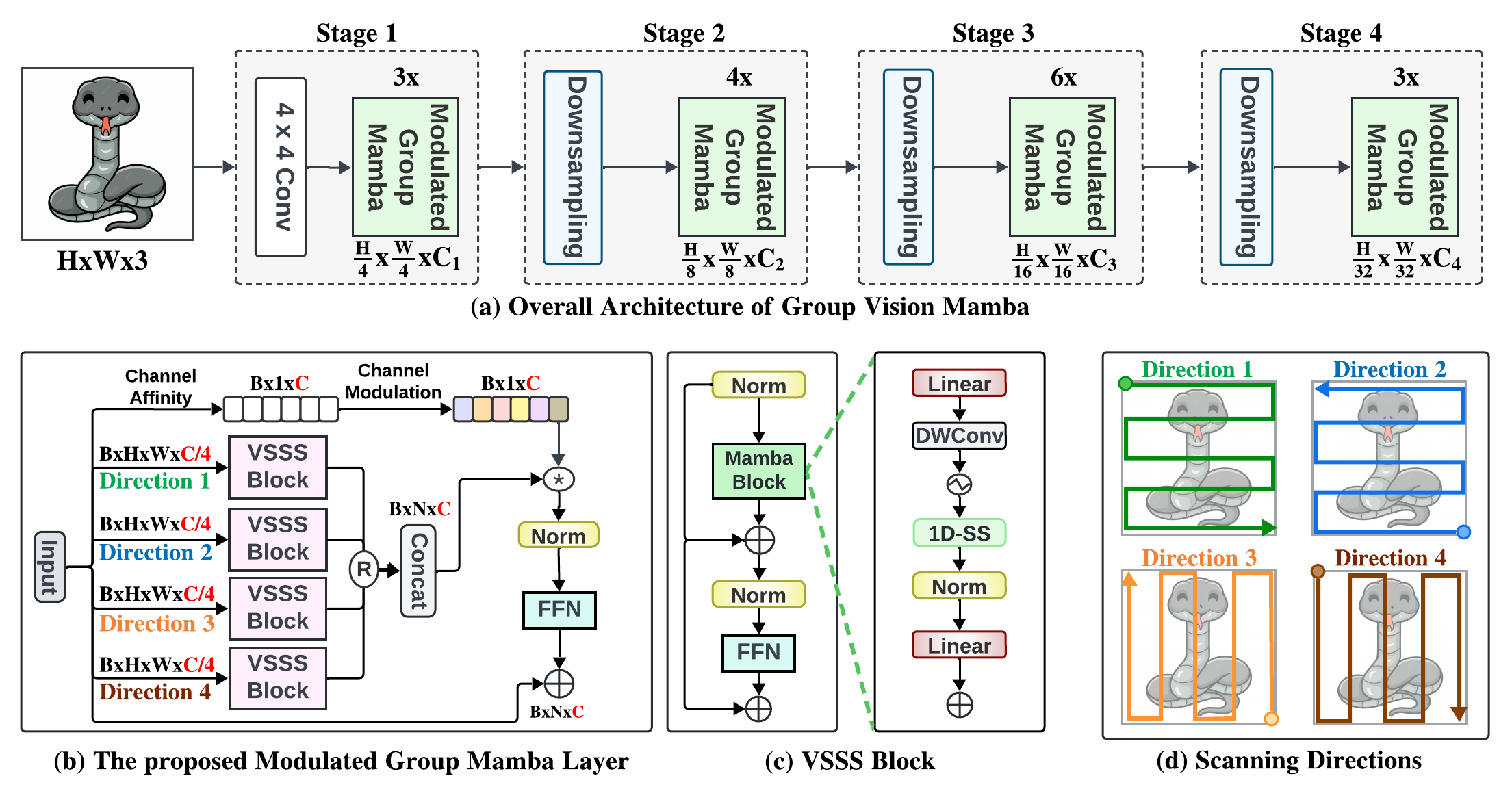
GroupMamba: Efficient Group-Based Visual State Space Model [CVPR 2025]
Abdelrahman Shaker, Syed Talal, Salman Khan, Juergen Gall, Fahad Khan Paper / Code Our paper addresses the challenges of scaling SSM-based models for computer vision, particularly the instability and inefficiency of large model sizes. We introduce a parameter-efficient modulated group mamba layer that divides the input channels into four groups and applies our proposed SSM-based efficient Visual Single Selective Scanning (VSSS) block independently to each group, with each VSSS block scanning in one of the four spatial directions. The Modulated Group Mamba layer also wraps the four VSSS blocks into a channel modulation operator to improve cross-channel communication. Furthermore, we introduce a distillation-based training objective to stabilize the training of large models, leading to consistent performance gains. Our comprehensive experiments demonstrate the merits of the proposed contributions, leading to superior performance over existing methods for image classification on ImageNet-1K, object detection, instance segmentation on MS-COCO, and semantic segmentation on ADE20K. Our tiny variant with 23M parameters achieves state-of-the-art performance with a classification top-1 accuracy of 83.3% on ImageNet-1K, while being 26% efficient in terms of parameters, compared to the best existing Mamba design of same model size. |
|
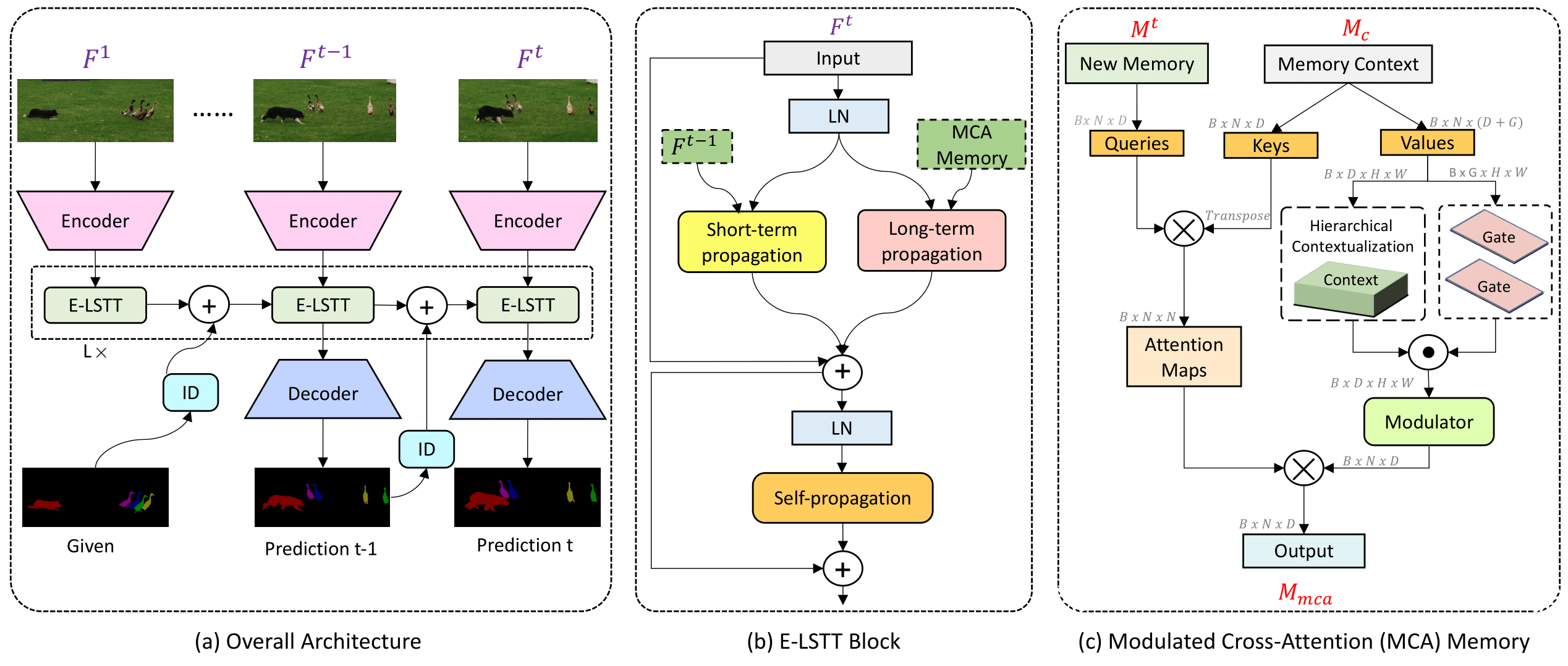
Efficient Video Object Segmentation via Modulated Cross-Attention Memory [WACV 2025]
Abdelrahman Shaker, Syed Talal, Martin Danelljan, Salman Khan, Ming-Hsuan Yang, Fahad Khan Paper / Code We propose an efficient transformer-based approach, named MAVOS, that introduces an optimized and dynamic long-term modulated cross-attention (MCA) memory to model temporal smoothness without requiring frequent memory expansion. The proposed MCA effectively encodes both local and global features at various levels of granularity while efficiently maintaining consistent speed regardless of the video length. Extensive experiments on multiple benchmarks, LVOS, Long-Time Video, and DAVIS 2017, demonstrate the effectiveness of our proposed contributions leading to real-time inference and markedly reduced memory demands without any degradation in segmentation accuracy on long videos. Compared to the best existing transformer-based approach, our MAVOS increases the speed by 7.6X, while significantly reducing the GPU memory by 87% with comparable segmentation performance on short and long video datasets. |
|
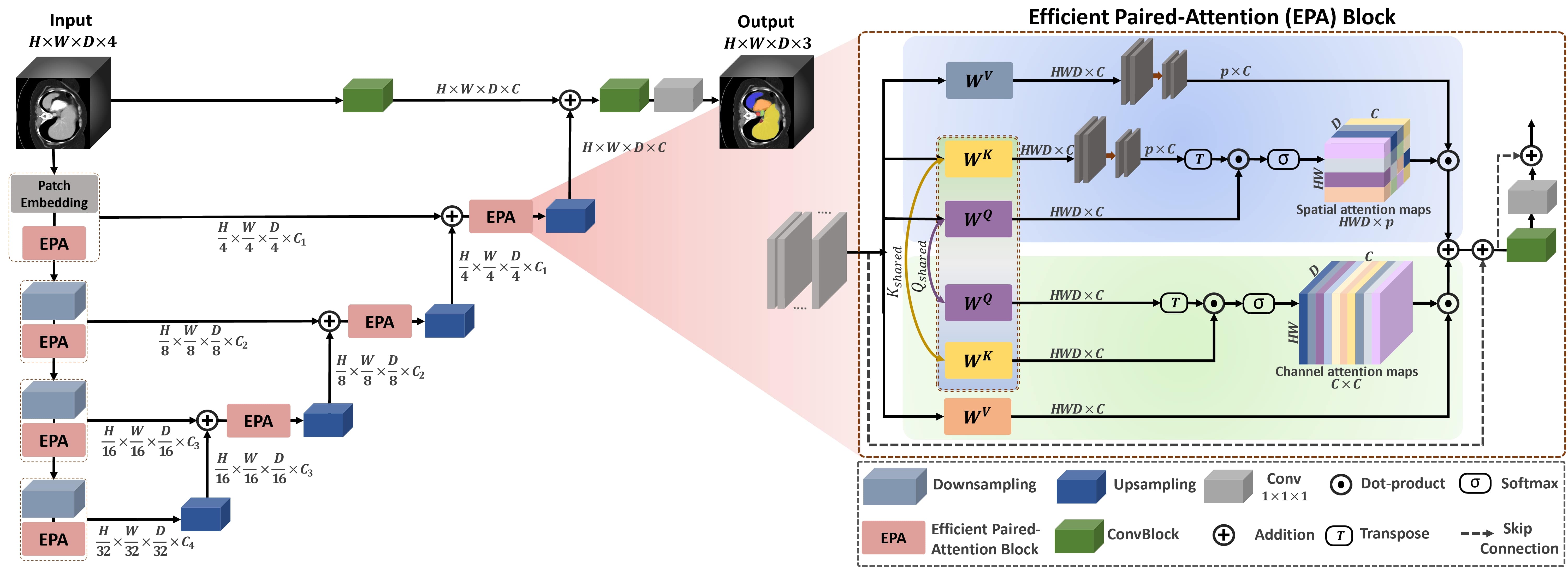
UNETR++: Delving into Efficient and Accurate 3D Medical Image Segmentation [IEEE TMI-2024] (Journal IF: 10.6)
Abdelrahman Shaker, Muhammad Maaz, Hanoona Rashed, Salman Khan, Ming-Hsuan Yang, Fahad Khan Project page / Paper / Code In this paper, we propose a 3D medical image segmentation approach, named UNETR++, that offers both high-quality segmentation masks as well as efficiency in terms of parameters and compute cost. The core of our design is the introduction of a novel efficient paired attention (EPA) block that efficiently learns spatial and channel-wise discriminative features using a pair of inter-dependent branches based on spatial and channel attention. Our spatial attention formulation is efficient having linear complexity with respect to the input sequence length. To enable communication between spatial and channel-focused branches, we share the weights of query and key mapping functions that provide a complimentary benefit (paired attention), while also reducing the overall network parameters. Our extensive evaluations on three benchmarks, Synapse, BTCV and ACDC, reveal the effectiveness of the proposed contributions in terms of both efficiency and accuracy. On Synapse dataset, our UNETR++ sets a new state-of-the-art with a Dice Similarity Score of 87.2%, while being significantly efficient with a reduction of over 71% in terms of both parameters and FLOPs, compared to the best existing method in the literature. |
|
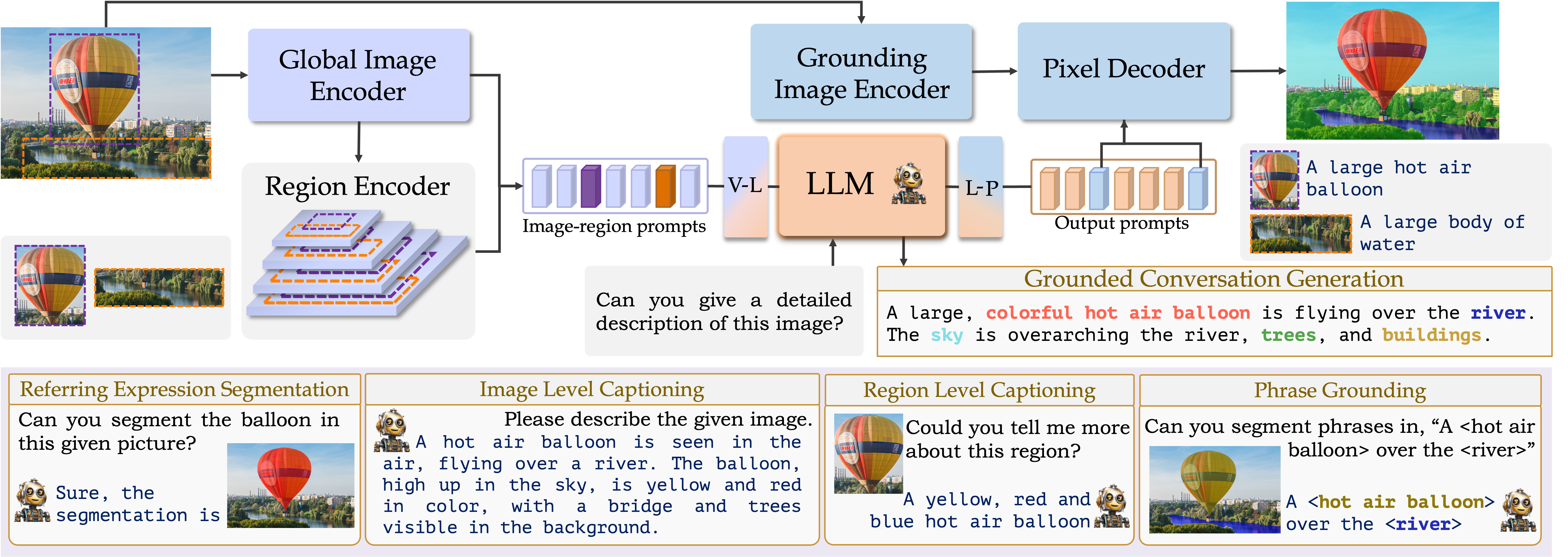
GLaMM: Grounding Large Multimodal Model [CVPR 2024]
Muhammad Maaz, Hanoona Rashed, Sahal Shaji, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao Muhammad Anwer, Eric Xing, Ming-Hsuan Yang, Fahad Khan Project page / Paper / Code Grounding Large Multimodal Model (GLaMM) is an end-to-end trained LMM which provides visual grounding capabilities with the flexibility to process both image and region inputs. This enables the new unified task of Grounded Conversation Generation that combines phrase grounding, referring expression segmentation, and vision-language conversations. Equipped with the capability for detailed region understanding, pixel-level groundings, and conversational abilities, GLaMM offers a versatile capability to interact with visual inputs provided by the user at multiple granularity levels. |
|
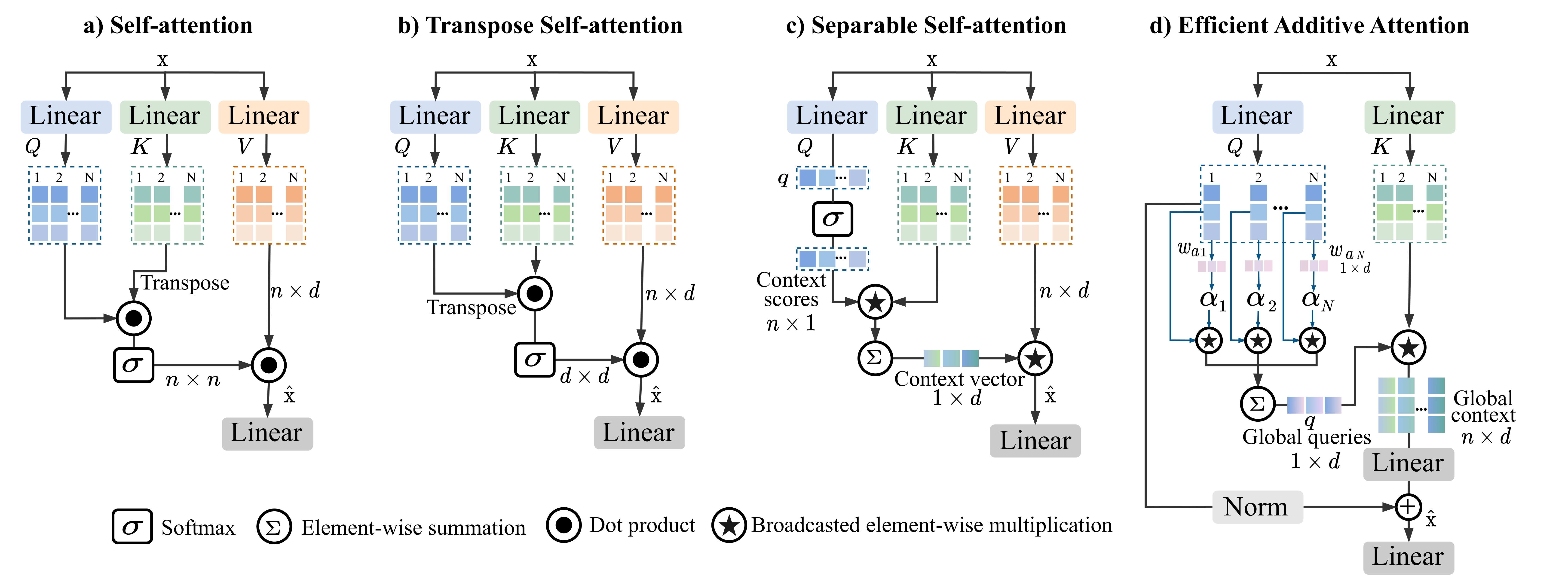
SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications [ICCV 2023]
Abdelrahman Shaker, Muhammad Maaz, Hanoona Rashed, Salman Khan, Ming-Hsuan Yang, Fahad Khan Paper / Code Self-attention has become a defacto choice for capturing global context in various vision applications. However, its quadratic computational complexity with respect to image resolution limits its use in real-time applications, especially for deployment on resource-constrained mobile devices. Although hybrid approaches have been proposed to combine the advantages of convolutions and self-attention for a better speed-accuracy trade-off, the expensive matrix multiplication operations in self-attention remain a bottleneck. In this work, we introduce a novel efficient additive attention mechanism that effectively replaces the quadratic matrix multiplication operations with linear element-wise multiplications. Our design shows that the key-value interaction can be replaced with a linear layer without sacrificing any accuracy. Unlike previous state-of-the-art methods, our efficient formulation of self-attention enables its usage at all stages of the network. Using our proposed efficient additive attention, we build a series of models called "SwiftFormer" which achieves state-of-the-art performance in terms of both accuracy and mobile inference speed. Our small variant achieves 78.5% top-1 ImageNet-1K accuracy with only 0.8~ms latency on iPhone 14, which is more accurate and 2x faster compared to MobileViT-v2. |
|
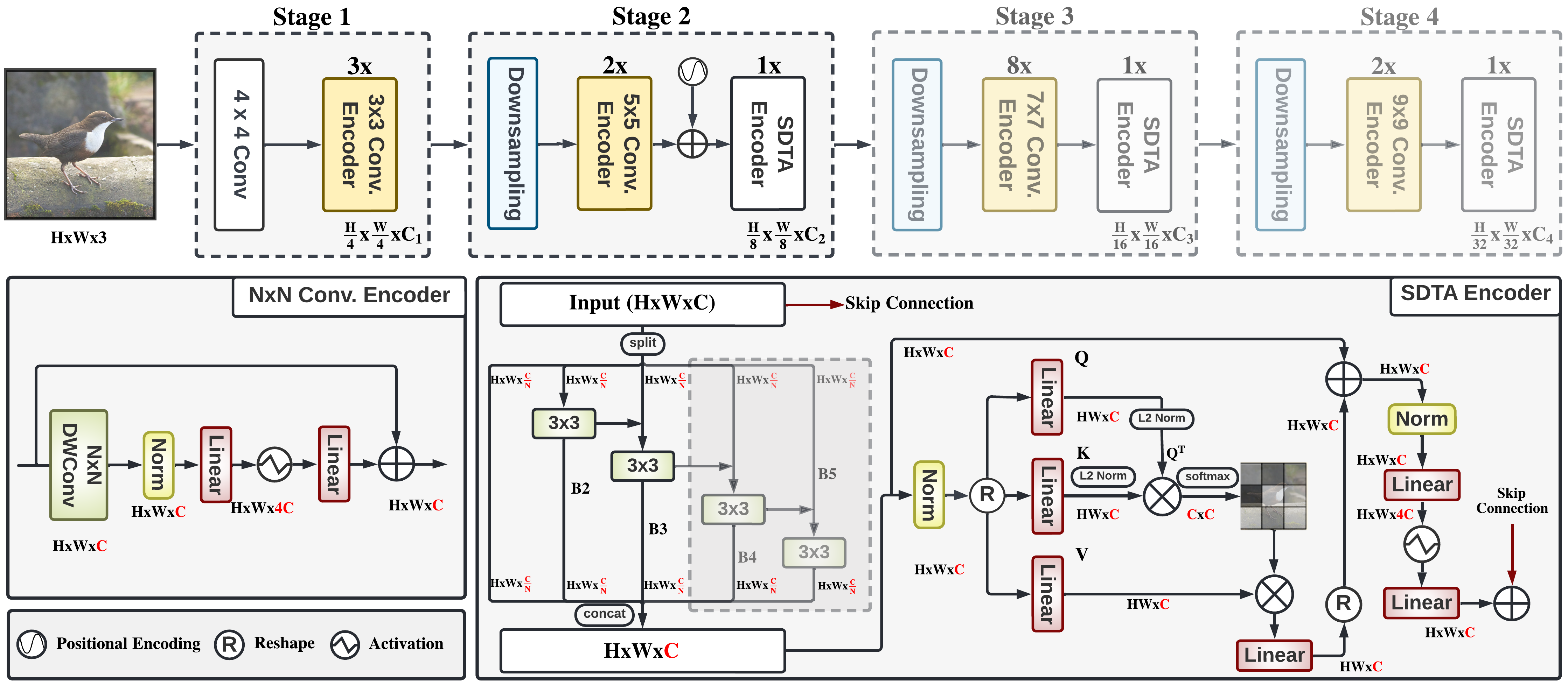
EdgeNeXt: Efficiently Amalgamated CNN-Transformer Architecture for Mobile Vision Applications [ECCVW 2022]
Muhammad Maaz, Abdelrahman Shaker (First author equal contribution), Hisham Cholakkal, Salman Khan, Syed Waqas Zamir, Rao Muhammad Anwer, Fahad Khan Project page / Paper / Code & Model weights We present EdgeNeXt, a new hybrid architecture that effectively combine the strengths of both CNN and Transformer models. Specifically in EdgeNeXt, we introduce split depth-wise transpose attention (SDTA) encoder that splits input tensors into multiple channel groups and utilizes depth-wise convolution along with self-attention across channel dimensions to implicitly increase the receptive field and encode multi-scale features. Our extensive experiments on classification, detection and segmentation tasks, reveal the merits of the proposed approach, outperforming state-of-the-art methods with comparatively lower compute requirements. Our EdgeNeXt model with 1.3M parameters achieves 71.2% top-1 accuracy on ImageNet-1K, outperforming MobileViT with an absolute gain of 2.2% with 28% reduction in FLOPs. Further, our EdgeNeXt model with 5.6M parameters achieves 81.1% (with knowledge distillation) and 79.4% (without knowledge distillation) top-1 accuracy on ImageNet-1K. |

|
INSTA-YOLO: Real-Time Instance Segmentation [ICMLW 2021]
Eslam Bakr, Abdelrahman Shaker, (First author equal contribution), Ahmed El-Sallab, Mayada Hadhoud Paper We propose Insta-YOLO, a novel one-stage end-to-end deep learning model for real-time instance segmentation. Instead of pixel-wise prediction, our model predicts instances as object contours represented by 2D points in Cartesian space. We evaluate our model on three datasets, namely, Carvana,Cityscapes and Airbus. We compare our results to the state-of-the-art models for instance segmentation. The results show our model achieves competitive accuracy in terms of mAP at twice the speed on GTX-1080 GPU |
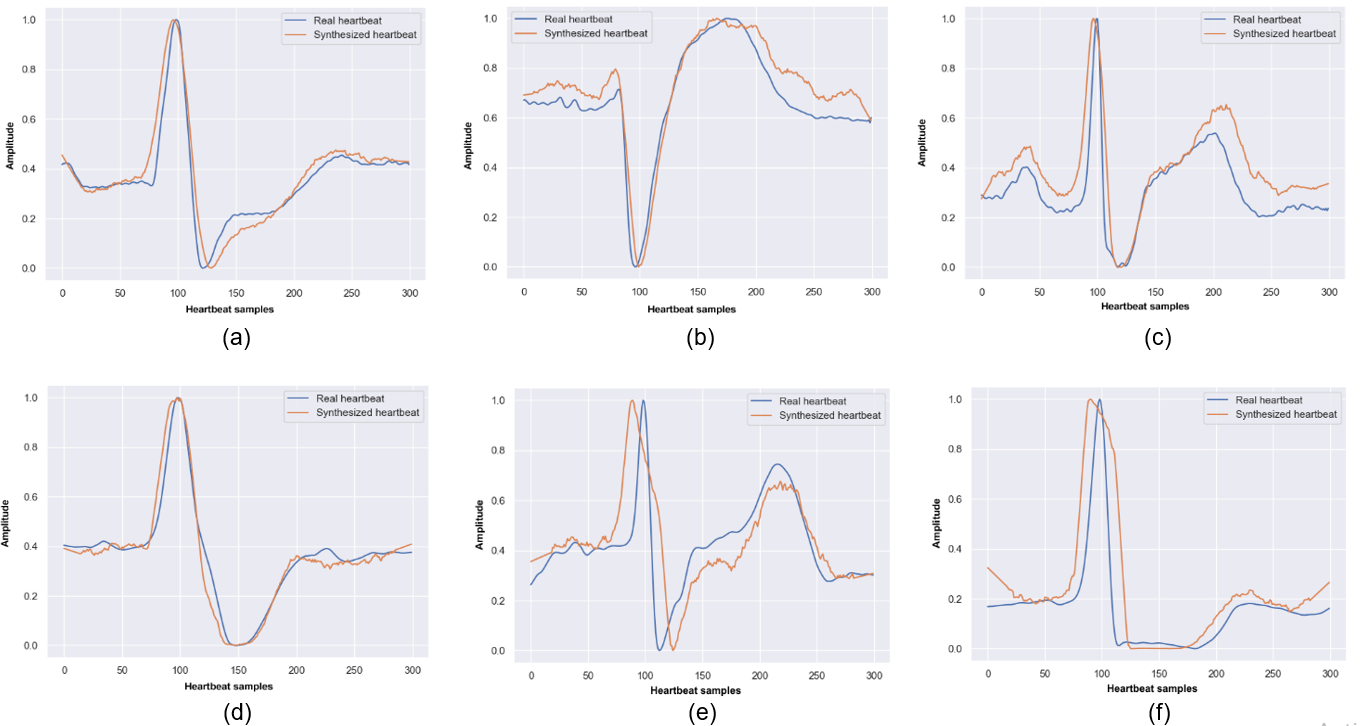
|
Generalization of Convolutional Neural Networks for ECG Classification Using Generative Adversarial Networks [IEEE Access 2020]
Abdelrahman Shaker, Manal Tantawi, Howida Shedeed, Mohamed Tolba Paper We propose a novel data-augmentation technique based on generative adversarial networks (GANs) to restore the balance of the MITBIH dataset. Then, two deep learning approaches—an end-to-end approach and a two-stage hierarchical approach—based on deep convolutional neural networks (CNNs) are used for heartbeat classification. Results show that augmenting the original imbalanced dataset with generated heartbeats by using the proposed techniques more effectively improves the performance of ECG classification than using the same techniques trained only with the original dataset. Furthermore, we demonstrate that augmenting the heartbeats using GANs outperforms other common data augmentation techniques. |
News |
Achievements |
Academic Service |
Teaching |
Students |
PhD StudentsResearch Area: Cross-modality alignment
Research Area: Video generation and understanding
Research Area: Unified multi-modals
MSc Students[Coming soon]
|