Muhammad Maaz, Abdelrahman Shaker, Hisham Cholakkal, Salman Khan, Syed Waqas Zamir, Rao Muhammad Anwer, and Fahad Khan
Overview

Our proposed EdgeNeXt model runs in real time on NVIDIA Jetson Nano edge device, and achieves state-of-the-art accuracy of 79.4% on ImageNet-1K with only 5.6M parameters and 1.3G MAdds. The same model achieves 81.1% accuracy when trained using USI.
Abstract
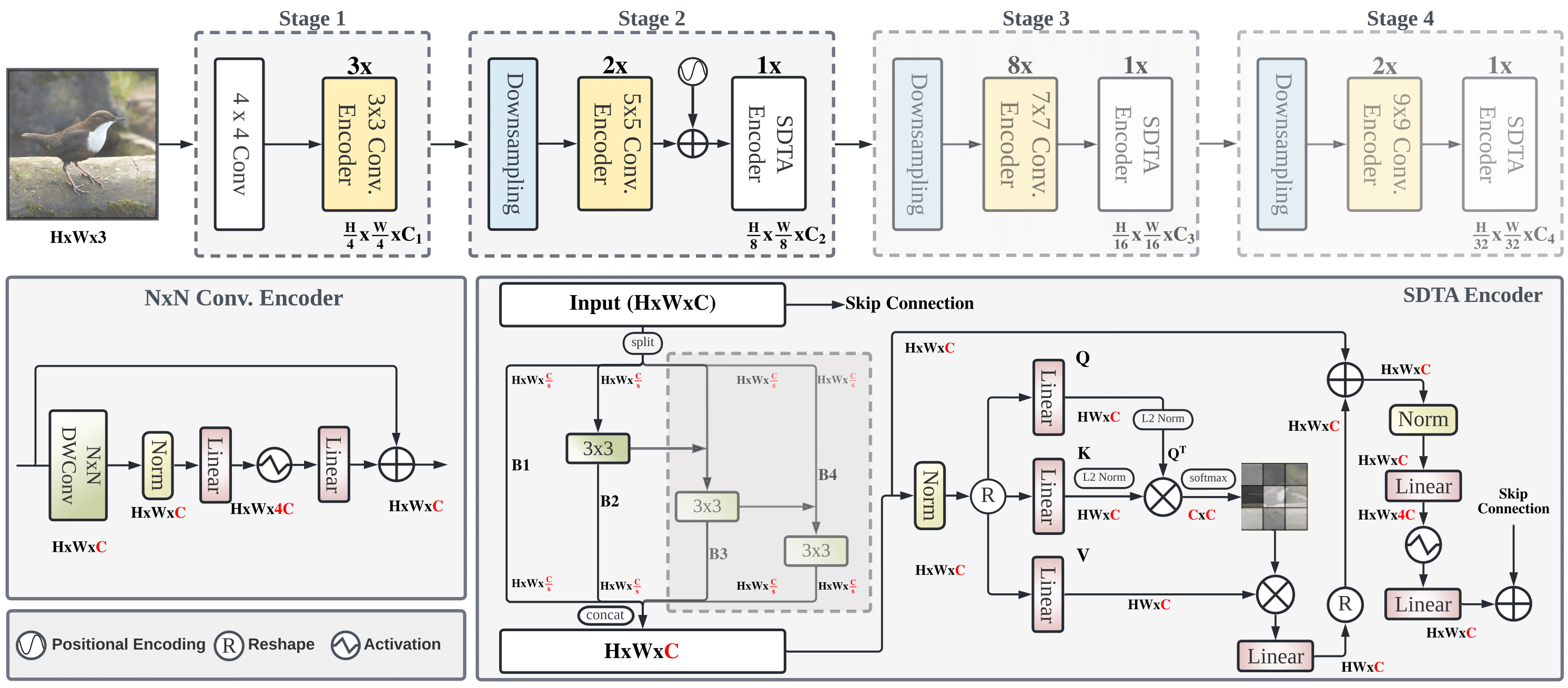
In the pursuit of achieving ever-increasing accuracy, large and complex neural networks are usually developed. Such models demand high computational resources and therefore cannot be deployed on edge devices. It is of great interest to build resource-efficient general purpose networks due to their usefulness in several application areas. In this work, we strive to effectively combine the strengths of both CNN and Transformer models and propose a new efficient hybrid architecture EdgeNeXt. Specifically in EdgeNeXt, we introduce split depth-wise transpose attention (SDTA) encoder that splits input tensors into multiple channel groups and utilizes depth-wise convolution along with self-attention across channel dimensions to implicitly increase the receptive field and encode multi-scale features. Our extensive experiments on classification, detection and segmentation tasks, reveal the merits of the proposed approach, outperforming state-of-the-art methods with comparatively lower compute requirements. Our EdgeNeXt model with 1.3M parameters achieves 71.2% top-1 accuracy on ImageNet-1K, outperforming MobileViT with an absolute gain of 2.2% with 28% reduction in FLOPs. Further, our EdgeNeXt model with 5.6M parameters achieves 79.4% top-1 accuracy on ImageNet-1K.
Model Zoo
| Name | Acc@1 | #Params | MAdds | Model |
|---|---|---|---|---|
| edgenext_small_usi | 81.07 | 5.59M | 1.26G | model |
| edgenext_small | 79.41 | 5.59M | 1.26G | model |
| edgenext_x_small | 74.96 | 2.34M | 538M | model |
| edgenext_xx_small | 71.23 | 1.33M | 261M | model |
| edgenext_small_bn_hs | 78.39 | 5.58M | 1.25G | model |
| edgenext_x_small_bn_hs | 74.87 | 2.34M | 536M | model |
| edgenext_xx_small_bn_hs | 70.33 | 1.33M | 260M | model |
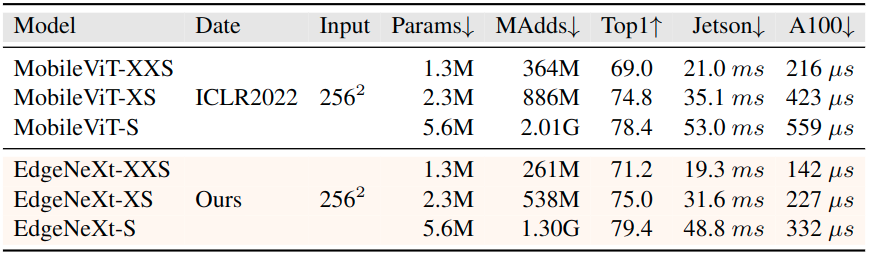
Comparison with Previous SOTA MobileViT (ICLR-2022)
Qualitative Results (Segmentation)

Qualitative Results (Detection)

Citation
@article{Maaz2022EdgeNeXt,
title={EdgeNeXt: Efficiently Amalgamated CNN-Transformer Architecture for Mobile Vision Applications},
author={Muhammad Maaz and Abdelrahman Shaker and Hisham Cholakkal and Salman Khan and Syed Waqas Zamir and Rao Muhammad Anwer and Fahad Shahbaz Khan},
journal={2206.10589},
year={2022}
}
Contact
Should you have any question, please create an issue on our repository or contact us at muhammad.maaz@mbzuai.ac.ae & abdelrahman.youssief@mbzuai.ac.ae